4/19~30
(내가 다니는 회사는 교육도 시켜주고 좋은 회사다.)
(기초 내용 생략. 코드 위주)
<Advanced Technique>
1. Data organization
1) Train/Validation/Test
Train set: training model parameters
Validation set: hyperparameter search
Test set
2) How to split train/val/test sets?
- How big "m" is
Small scale: m<=1,000 --> train:val:test = 60:20:20
Middle: 1,000 <= m <= 10,000 --> 80:10:10
Large: 10,000 <= m <= 1,000,000 --> 98:1:1
- Data distribution
Target dist. -> Test set dist. -> Val set dist.
(tensorflow code)
from sklearn.model_selection import train_test_split
X_, X_test, y_, y_test = train_test_split(X, y, test_size=1/10, stratify=y, random_state=42)
2. Generalization (총 4가지)
1) Regularization
- Motivation
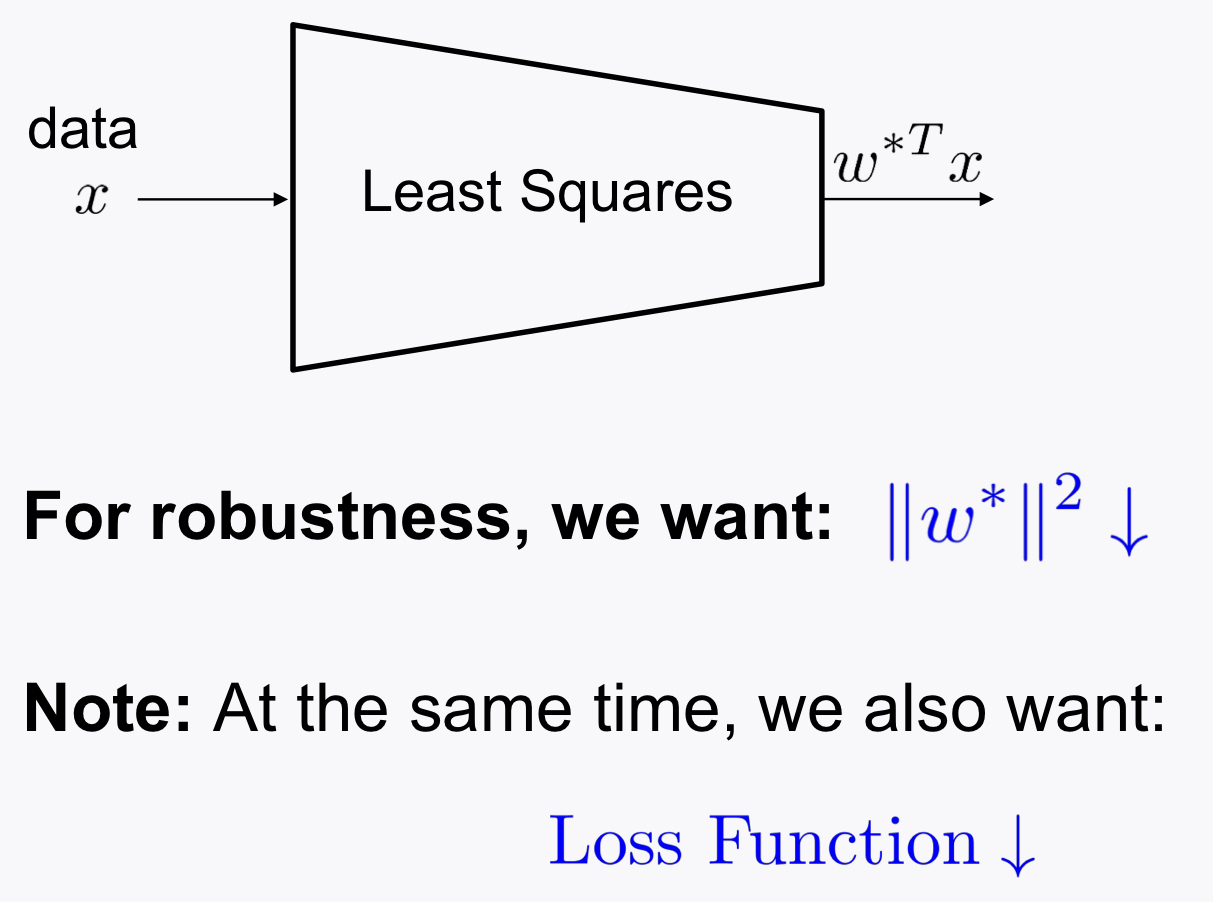
- Idea

λ : regularization factor (hyperparameter)
(tensorflow code, L2)
from tensorflow.keras.regularizers import l2
(layer add 단계에서)
lambda_ = 0.1 #default값 이용해도 돼
model.add(Dense(128, activation='relu', kernel_regularizer=l2(lambda_), bias_regularizer=l2(lambda_), kernel_initializer='he_normal'))
2) Data Augmentation
Rotation / Mirroring / Cropping
3) Early Stopping (항상 쓴다고 생각해야돼)
Epochs 증가 --> More overfitting to train set
To avoid overfitting: Rely on validation loss
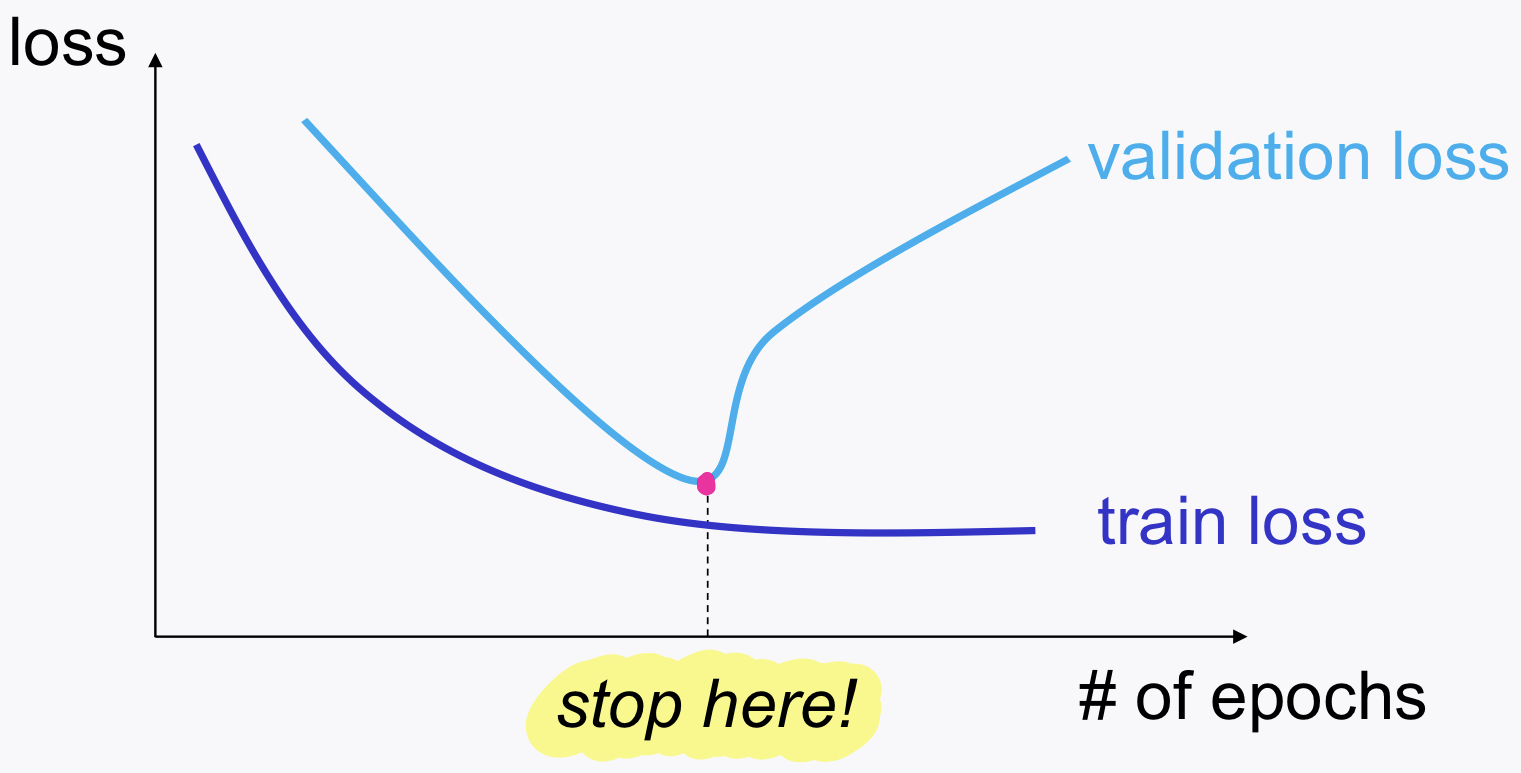
(tensorflow code)
- Epochs Control
from tensorflow.keras.callbacks import EarlyStopping, LearningRateScheduler
es_callback = EarlyStopping(monitor='val_acc', patience=3)
hist = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=10, verbose=0, callbacks=[es_callback])
4) Dropout (DNN 특화)
For each training step and per example:
Randomly remove nuerons independently across them.
(tensorflow code)
from tensorflow.keras.layers import Dense, Dropout
(layer 사이에)
model.add(Dropout(rate=0.7))
3. Weight initialization
4. Techniques for training stability
(Adam/ Learning rate decay / BN)
1) Learning rate decay
(tensorflow code)
※ 함수를 만들어야 됨
def scheduler(epoch, lr):
if epoch in [30, 60]:
lr = lr*0.01
return lr
lrs_callback = LearningRateScheduler(scheduler) #rule
hist = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=10, verbose=0, callbacks=[lrs_callback])
2) Batch normaliztion
(tensorflow code)
from keras.layers import Conv2D, Flatten, Dense, MaxPool2D, Input, Add, ReLU, BatchNormalization
inputs=Input(shape=(32,32,3))
x = Conv2D(32,kernel_size=(3,3),strides=(1,1),padding='same')(inputs)
x = BatchNormalization()(x)
x = ReLU()(x)
'일개미의 생활 ∙̑◡∙̑ > 공부' 카테고리의 다른 글
| Lesson4-8: Logistic Regression (1) | 2021.09.21 |
|---|---|
| Lesson2: The Machine Learning Workflow 마무리 (2) | 2021.08.17 |
| Lesson2-10. Exercise: Choosing Metrics (iou.py, precision_recall.py ) (1) | 2021.08.03 |



댓글